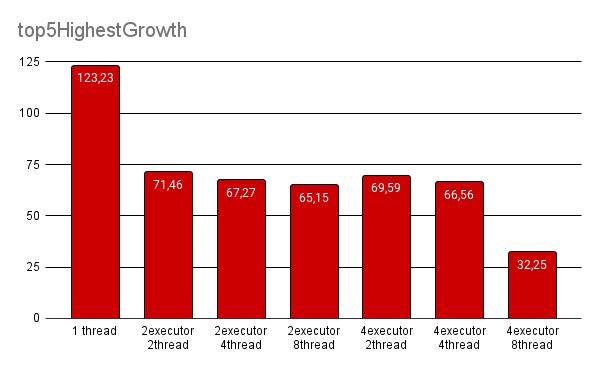
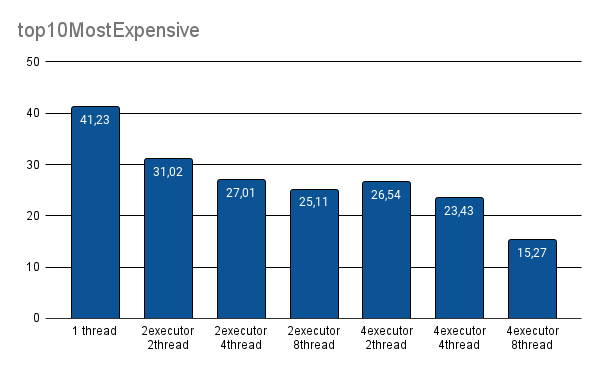
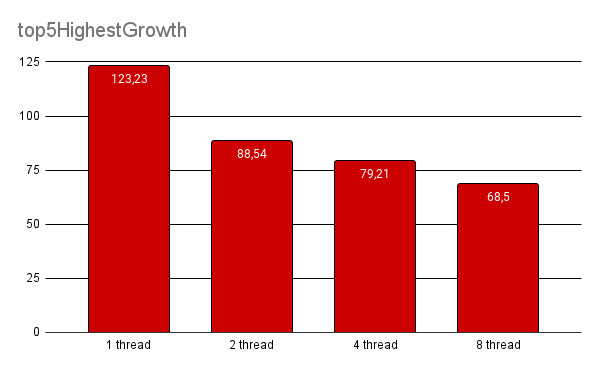
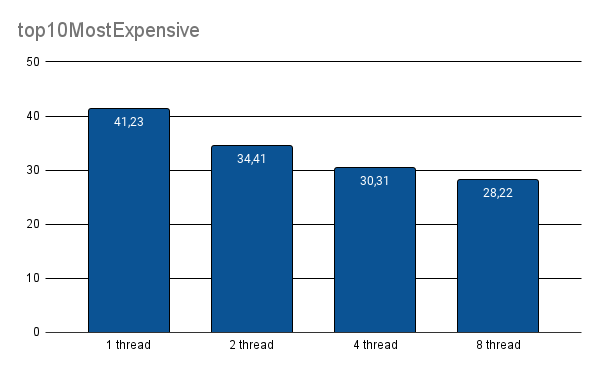
Some of these functions are:
- pyspark.sql.DataFrame.agg: This method is used to perform aggregation operations. It is used to calculate sums, averages, maximums, and other types of aggregates on one or more columns of the DataFrame.
df.agg(max(col("close"))) # takes the maximum value of the close column
- pyspark.sql.DataFrame.withColumn: This method is used to add a new column or to replace an existing one with a column expression.
df.withColumn("close", col("close").cast("float"))
# convert the value in the "close" column from type string to type float
- pyspark.sql.functions.lag: This function is a window function (pyspark.sql.window.lag) and is used to get the value of a column in a previous row.
df.withColumn("prev_value", f.lag(f.col("close"))) # create a column with the previous value of close
- pyspark.sql.functions.to_date: This function is used to convert a column of type String to a column of type Date. We can specify the date format through its second parameter (e.g. dd-MM-yyyy).
df.withColumn("date", f.to_date(df[0])) # convert the values of the "date" column from string to DateType()
- pyspark.sql.DataFrame.drop: This method is used to remove one or more columns.
df.drop("prev_value") # we remove the column "prev_value"